Software and Science in Equal Measure
 Manhattan Metric
Manhattan Metric
Eureka - Part 1
I have found it!
Within the field of machine learning there is a problem that has been known about for over 35 years that goes by the name “Catastrophic Forgetting”. The crux of this problem is that, when we train a neural net on one topic, then attempt to train it on a separate topic, it will largely forget what it learned about the first topic. While, over the years, the field has developed a variety of techniques for working around the problem of catastrophic forgetting, it has been taken as a given that the problem remains.
I have found a way to overcome catastrophic forgetting and enable a neural net to continuously learn new information without forgetting the old.
I think…
Science is hard, but not for the reasons you might think. Yes, if you want to be a scientist there are many things you must learn. You need to know a lot of math. You need to understand logic. You need to memorize equations and facts and read many, many, many papers. All that is true, but that is not the hard part.
The hard part of science is the doubt. Being successful at science requires simultaneously believing that you have found some new knowledge while also doubting that what you have found is real. You must be willing to be your own worst critic and, when it seems like that internal critic is correct, be willing to press forward anyway.
So, sitting with my own doubt fast at hand, I’d like to walk through the process of doing science and what has brought me to a place where, I think, I have found it.
I have applied for a patent, and there is a paper forthcoming that will describe everything in scientific detail. I am in the process of cleaning up my somewhat cluttered code repository and will be sharing that soon as well. Before all that, though, I wanted to share the story of how I arrived at this place. I do this partly as an exercise in scientific communication, but mostly I do it as a way for me to gather my thoughts and tamp down that demon of doubt that is the sidekick to any good scientist.
Extraordinary Claims
There is a tenet in science that “extraordinary claims require extraordinary evidence”, and the claim that I have just made is extraordinary. It is only right that I should be expected to provide evidence. To that end, and to jump to the end, here is the last figure I have prepared that managed to convince me that I had any right to make the claim I have made:
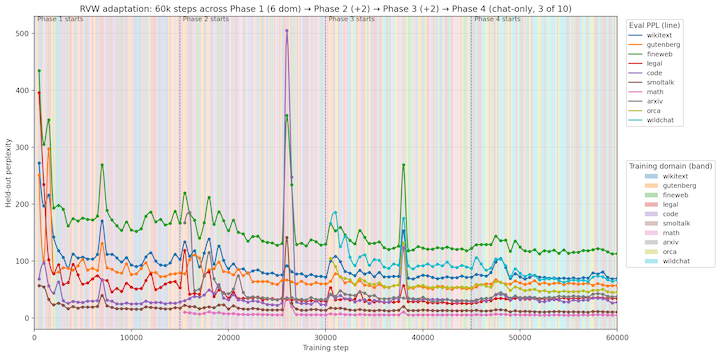
If I am correct, this finding has the possibility of turning the entire practice of Artificial Intelligence on its head. Just for starters, it would mean that much of the massive compute power and behemoth data centers that are being assembled by the largest players in the AI space are, largely, unnecessary. More fundamentally, it would mean that AI models would no longer be relegated to being static answer machines. Instead, they would accumulate knowledge and experience and, dare I say it, a “personality” of a sort. No longer would there be “the” ChatGPT, but there could be my ChatGPT and your ChatGPT, each with their own different set of knowledge based on what you or I had told it over its lifetime.
I actually showed this figure to Google Gemini and asked it to give a rundown of the potential implications. You can read its full response here.
Of course, a single figure is not extraordinary evidence. Furthermore, simply making a claim is not nearly as interesting as exploring the how and why behind the claim. We often forget that Charles Darwin’s claim of descent with modification as a driver of natural selection was originally missing the critical “how” that an Austrian monk by the name of Gregor Mendel later provided. A likely apocryphal tale has it that Mendel’s work was found, unread, on Darwin’s desk after his death.
Ok, with that background out of the way, now that the stage is set…
Introducing: RVW
I have discovered a technique for modifying transformer-based large language models in a way that enables them to learn continuously. This technique does not expand parameters. It does not utilize replay buffers or external memory systems. It does not require task or domain labels. It is resistant to randomized and adversarial training curricula. It is applicable to a variety of different model architectures and operates at scales up to 5 billion parameters (the largest I was practically able to test on my MacBook Pro M4 Max). Most importantly, it is resistant to catastrophic forgetting and, perhaps even more interestingly, learns domains more rapidly on second exposure to them, making up for any drift in knowledge that may have occurred.
Unless you are already deeply invested in the field of machine learning, much of that last paragraph may not mean much to you. My hope over this series of posts is to not only explain what all of this means, but to also convince you that what I have found is real and meaningful.
I will save why I have chosen the name “RVW” for later in the story.
In order to understand RVW, how it works, and why I thought to pursue it in the first place, we need to start at the beginning: Perceptrons…more on that next time.